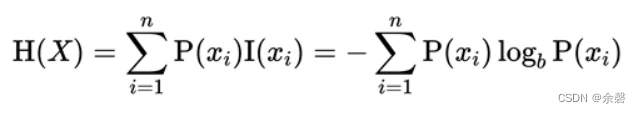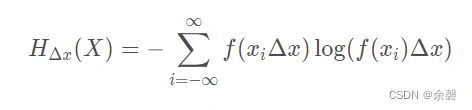1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| from scipy.io import loadmat
from sklearn.preprocessing import MinMaxScaler
from scipy import signal
import numpy as np
import math
import os
def compute_DE(signal):
variance = np.var(signal, ddof=1)
return math.log(2 * math.pi * math.e * variance) / 2
def load_data():
data_dir = "../SEED/Preprocessed_EEG/"
fs = 200
fStart = [0.5, 4, 8, 13, 32]
fEnd = [4, 8, 13, 32, 50]
channel = [3, 7, 13, 23]
filename_label = "label"
label = loadmat(data_dir + filename_label)
label = label["label"][0]
datasets_X, datasets_y = [], []
for filename_data in os.listdir(data_dir):
if filename_data in ["label.mat", "readme.txt"]:
continue
data_all = loadmat(data_dir + filename_data)
scenes = list(data_all.keys())[3:]
for index, scene in enumerate(scenes):
dataset_X = []
data = data_all[scene][channel]
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
for band_index, band in enumerate(fStart):
b, a = signal.butter(4, [fStart[band_index]/fs, fEnd[band_index]/fs], 'bandpass')
filtedData = signal.filtfilt(b, a, data)
filtedData_de = []
for lead in range(len(channel)):
filtedData_split = []
for de_index in range(0, filtedData.shape[1] - fs, fs):
filtedData_split.append(compute_DE(filtedData[lead, de_index: de_index + fs]))
if len(filtedData_split) < 265:
filtedData_split += [0.5] * (265-len(filtedData_split))
filtedData_de.append(filtedData_split)
filtedData_de = np.array(filtedData_de)
dataset_X.append(filtedData_de)
datasets_X.append(dataset_X)
datasets_y.append(label[index])
datasets_X, datasets_y = np.array(datasets_X), np.array(datasets_y)
if __name__ == "__main__":
datasets_X, datasets_y = load_data()
print(datasets_X.shape)
print(datasets_y.shape)
|